
Google’s New Robots.txt Update: What You Should Know
Google has made an update to its robots.txt guide, giving more precise instructions on how search engines handle the file and how site owners can optimize it for improved search visibility. The update seeks to dispel confusion regarding crawl directives, allowing webmasters to avoid indexing problems and enhance SEO performance.
Understanding Google’s Robots.txt Update
The robots.txt file is necessary for controlling which areas of a website search engines cannot or do not Google’s latest update describes how crawlers interpret these instructions and makes clear the distinction between blocking search bots from accessing content and blocking indexing.
Key Highlights: Greater Clarification on Robots.txt Directives: Google has laid out how Disallow, Allow, and Noindex are implemented so webmasters can properly set up their files.
- Better Indexing Insights: The change makes webmasters realize that preventing a page from being crawled does not necessarily mean that it will not be indexed, particularly in the case of a page with backlinks or other signals.
- Preventing SEO Blunders: Most webmasters unknowingly block important pages (such as CSS and JavaScript files), which negatively impacts their site’s performance and rankings. The new guidelines prevent such blunders.
- More specific actions you can take with robots.txt:
More specific things you can do with robots.txt: The robots.txt file is like a useful tool that you use to dictate what search engine spiders can or cannot do on your site. It can be just a couple of lines or more complex with individual rules for particular pages. Webmasters utilize it to resolve technical problems (such as excluding unnecessary pages from being crawled) or for privacy purposes (such as keeping specific content confidential). For instance, you could utilize robots.txt to prevent search engines from crawling duplicate pages or pages you wouldn’t want included in search results.
- Enhanced Indexing Understandings: The change assists webmasters in understanding that blocking a page from a crawl does not necessarily mean blocking it from getting indexed, particularly if the page contains backlinks or other indications.
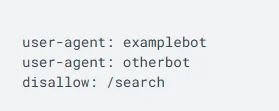
- Enhanced Indexing Understanding: The change informs site owners that blocking a page from crawling does not necessarily stop it from being indexed, particularly if the page contains backlinks or other factors.
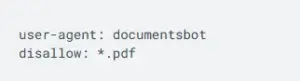
- Tell a bot it can crawl your blog, but not the drafts.
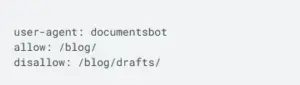
- Block a crawler from some portion of your site, yet let other crawlers onto your siteThis robots.txt file prohibits the specified aicorp-trainer-bot from viewing anything but the home page, while permitting other crawlers (e.g., search engines) to view the site.
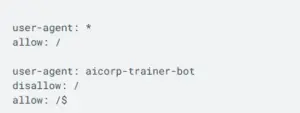
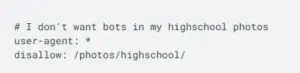
- Leave a comment for future youYou can begin a line with # to remind yourself why you placed a particular rule there.
What This Means for Webmasters
With this latest robots.txt update, webmasters should:
- Audit Their Robots.txt File: Make sure key pages are crawled by search engines while denying unnecessary ones.
- Use Google’s Testing Tools: Google Search Console offers a robots.txt tester to verify all the errors.
- Optimise Crawl Efficiency: Refrain from blocking key resources like images, CSS, and JavaScript, which affect rendering and ranking.
Conclusion
Google’s new robots.txt update guide on the importance of crawl management. Through their new guidelines, business owners and SEO professionals are able to maintain ease of crawling, prevent indexing problems, and contribute to the improvement of their website’s search engine ranking. Updating and testing robots.txt from time to time will make websites keep their visibility intact, and avoid major SEO errors.